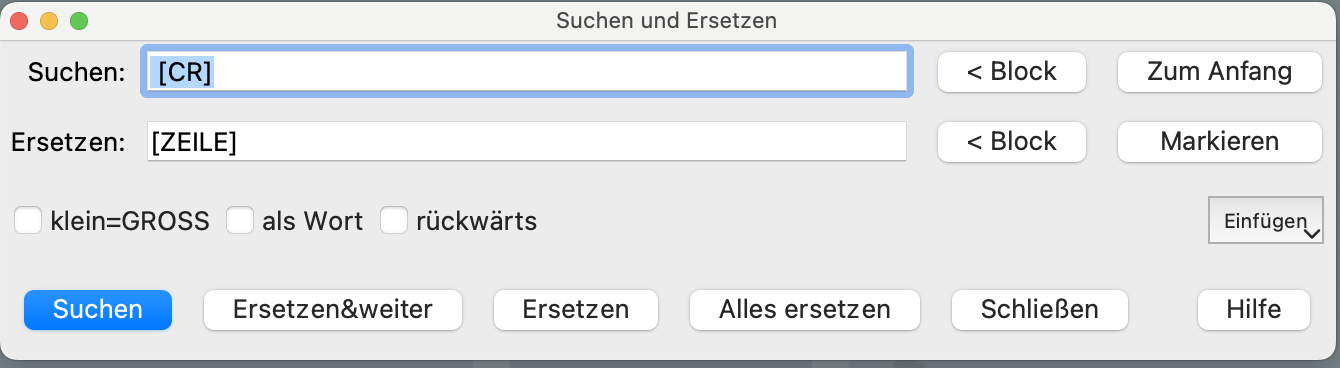
Diese finde ich nicht in Papyrus. Sie ist aber nötig, damit man Texte, wie diesen (s.u.), die nicht über die ganze Zeile gehen, umformatieren kann, z.B. für Google Translator. Sonst stimmt die Übersetzung nämlich nicht.
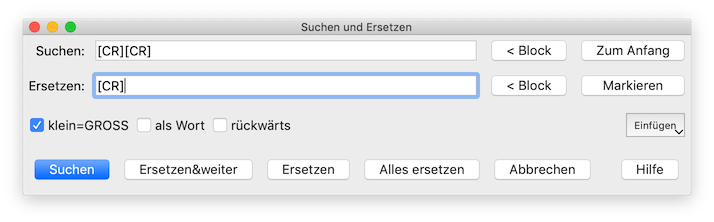
Bei dir enden die Textzeilen mit [CR] und danach kommt offenbar noch eine Leerzeile, die ohne weiteren Text gleich mit [CR] endet. Suche deshalb nach [CR][CR] und ersetze durch [CR]. Bitte keine Leerzeichen vor dem [CR] einsetzen, wie in deinem Bildschrimfoto zu sehen.
Ich habe deine obigen Zeilen kopiert und in Papyrus eingesetzt, da kommen keine Leerzeilen.
Also probiere einfach mal ein einfaches “[CR]” (s.o.) durch Leerzeichen zu ersetzen.
Wenn der Text markiert ist, wird er bei mir nicht gelöscht, aber ignoriert, d.h. das gesamte Dokument wird “behandelt”. Also ggf. den relevanten Teil temporär ausschneiden und in ein separates Dokument setzen. Oder testweise den Cursor an den Beginn des Teils setzen und mit “Ersetzen&weiter” arbeiten.
Aber es geht nicht darum, dass der Text Leerzeilen hat, sondern dass der Textumbruch zu früh erfolgt. Den würde ich gerne löschen, den Textumbruch. In Word geht das mit:Suchen → Absatzmarke → Ersetzen → (frei lassen).
Ich hab jetzt deinen Textausschnitt in ein Papyrus-Dokument eingefügt, dann Suchen/Ersetzen aufgerufen, unter Suchen [CR][CR] und unter Ersetzen ein Leerzeichen eingegeben. Dann auf den Button „zum Anfang” geklickt, damit der Cursor am Textanfang steht, und danach auf den Button „Alles ersetzen“. Es kommt die Meldung, dass 9 Textstellen ersetzt wurden und das Resultat sieht so aus: