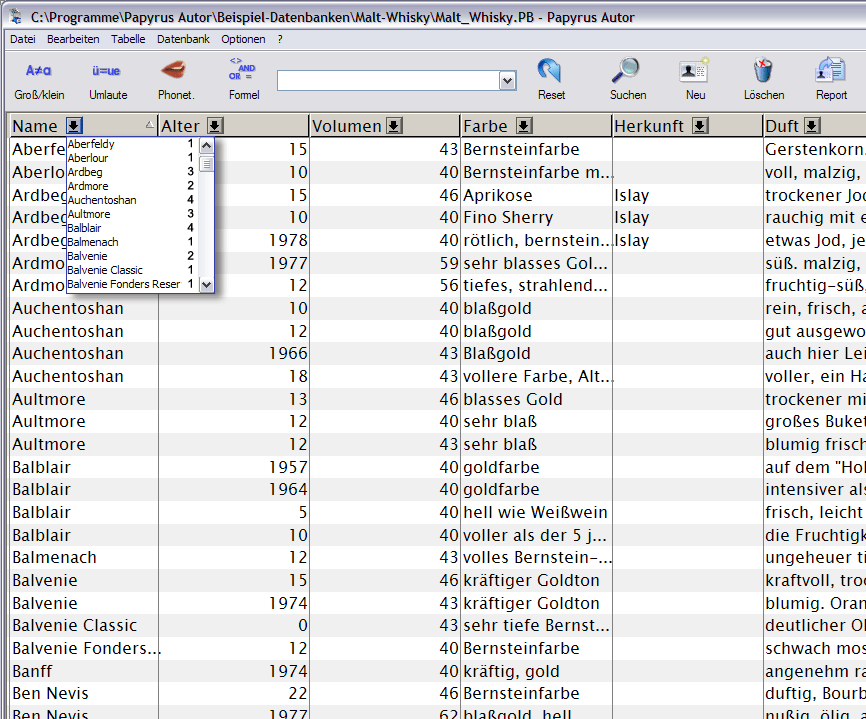
Man kennt es von Excel unter der Funktion AutoFilter (glaube ich):
Neben den Spaltenbezeichnungen (Datenfeldern) wird in der Tabellenansicht ein Pfeil angezeigt. Ein Klick darauf zeigt in einer aufklappenden Liste alle in der Datenbank vorkommenden Werte in diesem Feld, bei einer Datenbank mit Adressen im Feld Ort also bspw. München, Berlin, Hamburg usw.
Klickt man einen Wert an, kommen nur Datensätze mit diesem Wert.
Vorteile:
- Man hat schnell eine Suche ausgeführt, ohne Tippen.
Man hat schnell eine Liste mit Datensätzen derselben Eigenschaft
Für ( z. B. Adressdatenbank) jeden Ort wird nur ein Eintrag angezeigt, unabhängig davon, ob 1 oder 100 Datensätze für diesen Wert vorhanden sind
Fehleinträge werden schnell erkannt (z. B. wenn ein Eintrag “Hajburg” vorkommt, das müsste dann ja wohl Hamburg heissen…)
[/LIST]
Daran anknüpfend;
Wenn man (mehrere) Datensätze markiert und dann eine (weitere/ ergänzende) Suche ausführt, löscht Papyrus die vorherigen Markierungen wieder. Auch wenn man den betreffenden Befehl dazu nicht erteilt hat.
Blieben die Markierungen erhalten, könnte man Datensätze nach verschiedenen (!) Kriterien suchen und über die Markierung sammeln.
Beispiel: Ich würde gerne alle Adressen aus Berlin suchen und markieren. Dann noch die aus Potsdam und ebenfalls markieren. Danach würde ich gerne noch einige “per Hand” aussortieren, sprich die Markierung entfernen. Und abschließend dann einen Serienbrief an die markierten schicken.
Nur so als Anregung…